Linux Capabilities in a nutshell
Capabilities are being used by many Linux-based software nowadays to limit what a process can do. But I think the documentation is a bit hard to grasp and I found some parts of capabilities implementation confusing so I decided to condense my current knowledge into a shorter article.
The most important reference for capabilities is up-to-date man page capabilities(7). But that doesn’t provide an easy to read introduction.
Process Capabilities
Permissions of regular users are very limited, while permissions of “root” user are very powerful. But processes running under “root” often don’t require full root capabilities.
To help reduce “root” user power, POSIX capabilities provides a way to restrict groups of privileged system operations a process and its children are allowed to do. They basically divide full “root” privilege into a set of distinct privileges. The idea of capabilities was described in POSIX 1003.1e draft that was withdrawn in 1997.
Each Linux process (task) has five 64-bit numbers (sets) holding capability bits (used to be 32-bit before Linux 2.6.25) which can be inspected by reading /proc/<pid>/status
CapInh: 00000000000004c0
CapPrm: 00000000000004c0
CapEff: 00000000000004c0
CapBnd: 00000000000004c0
CapAmb: 0000000000000000
These numbers (here displayed as hex digits) are acting as a bitmap encoding a set of capabilities. Full names are:
- Inheritable – capabilities that children can inherit
- Permitted – capabilities the task is permitted to use
- Effective – capabilities actually effective
- Bounding set – prior to Linux 2.6.25, the bounding set was a system-wide attribute shared by all threads, probably meant to describe a set beyond which capabilities cannot grow. Currently it is per-task set. It is a part of execve transformation logic (more later) and also limits what a process can set to its inheritable set using capset().
- Ambient set (since Linux 4.3) – added to give capabilities to non-0 user easily, without using setuid or file capabilities (more later).
If a task asks to perform a privileged operation (like binding on ports < 1024), the kernel checks Effective bounding set to see if CAP_NET_BIND_SERVICE is set. If it is, it continues. Otherwise, it rejects the operation with EPERM (operation not permitted). These CAP_ defines in the kernel source are numbered sequentially so CAP_NET_BIND_SERVICE being 10 means a bit 1<<10 = 0x400 (that is the ‘4’ hex digit in my previous example).
The full human readable list of currently-defined capabilities can be found in your up-to-date manpage capabilities(7) (the one here is for reference only).
Additionally there is a library libcap to make capabilities management and inspection easier. In addition to library API, the package includes capsh utility which, among other things, allows printing its capabilities.
# capsh --print Current: = cap_setgid,cap_setuid,cap_net_bind_service+eip Bounding set =cap_setgid,cap_setuid,cap_net_bind_service Ambient set = Securebits: 00/0x0/1'b0 secure-noroot: no (unlocked) secure-no-suid-fixup: no (unlocked) secure-keep-caps: no (unlocked) secure-no-ambient-raise: no (unlocked) uid=0(root) gid=0(root) groups=0(root),1(bin),2(daemon),3(sys),4(adm),6(disk),10(wheel),11(floppy),20(dialout),26(tape),27(video)
There are a few confusing bits:
- Current – displays effective, inheritable and permitted capabilities of capsh process in cap_to_text(3) format. Again, it displays it in cap_to_text format which lists capabilities basically as capability[,capability…]+(e|i|p) groups, where ‘e’ means effective, ‘i’ inheritable and ‘p’ permitted. The list is not separated by ‘,’ as you would guess (cap_setgid+eip,cap_setuid+eip). The ‘,’ separates capabilities in a single +… (action) group. The actual list of action groups is then separated by spaces. So another example with two action groups would be “= cap_sys_chroot+ep cap_net_bind_service+eip”. And also these two action groups “= cap_net_bind_service+e cap_net_bind_service+ip” would encode the same meaning as a single “cap_net_bind_service+eip”.
- Bounding set/Ambient set. To make things even more confusing, these two lines contain just a list of capabilities set in those sets, separated by spaces. No cap_to_text format is used here because it is not listing permitted, effective, inheritable sets together but just a single (bounding/ambient) set.
- Securebits: displays task’s securebits integer in as decimal/hex/fancy-verilog-convention-for-binary-strings (yes, everyone would expect it here and it’s totally clear by ‘b because every sysadmin programs its own FPGAs and ASICs). The state of securebits follows. The actual bits are defined as SECBIT_* in securebits.h and also described in capabilities(7).
- The tool lacks the one important state and that is the “NoNewPrivs” which can be also seen by inspecting /proc/<pid>/status. That is described in prctl(2) only, even though it directly affects capabilities when used in conjunction with file capabilities (more later). NoNewPrivs is described as “With no_new_privs set to 1, execve(2) promises not to grant privileges to do anything that could not have been done without the execve(2) call (for example, rendering the set-user-ID and set-group-ID mode bits, and file capabilities non-functional). Once set, this the no_new_privs attribute cannot be unset. The setting of this attribute is inherited by children created by fork(2) and clone(2), and preserved across execve(2).“. This is the flag which Kubernetes sets to 1 when allowPrivilegeEscalation is set to false in pod’s securityContext.
When a process starts a new process by doing execve(2), capabilities are transformed to the child using the formula mentioned in capabilities(7):
P'(ambient) = (file is privileged) ? 0 : P(ambient)
P'(permitted) = (P(inheritable) & F(inheritable)) |
(F(permitted) & P(bounding)) | P'(ambient)
P'(effective) = F(effective) ? P'(permitted) : P'(ambient)
P'(inheritable) = P(inheritable) [i.e., unchanged]
P'(bounding) = P(bounding) [i.e., unchanged]
where:
P() denotes the value of a thread capability set before the
execve(2)
P'() denotes the value of a thread capability set after the
execve(2)
F() denotes a file capability set
These rules describe action taken for every bit in ambient/permitted/effective/inheritable/bounding sets. It uses standard C syntax (& for logic AND, | for logic OR). P’ is the child process, P is the current process calling execve(2). F are so called “file capabilities” of the file being execve’d.
Additionaly, a process can programmatically change its inheritable, permitted and effective sets using libpcap any time according to these rules:
- Unless the caller have the CAP_SETPCAP, the new inheritable set must be a subset of P(inheritable) & P(permitted)
- (since Linux 2.6.25) The new inheritable set must be a subset of P(inheritable) & P(bounding)
- The new permitted set must be a subset of P(permitted)
- The new effective set must be a subset of P(effective)
As HN user eqvinox suggested, pspax from pax-utils can be used to list capabilities of running processes, just compile it with libpcap support (make USE_CAP=yes):
# pspax USER PID PAX MAPS ETYPE NAME CAPS ATTR root 60879 --- w^x ET_DYN crond =ep system_u:system_r:kernel_t:s0 root 60910 --- w^x ET_DYN ntpd cap_net_bind_service,cap_ipc_lock,cap_sys_time=ep system_u:system_r:kernel_t:s0
File capabilities
Sometimes a user with a reduced set of capabilities needs to run a binary which requires more capabilities. Previously, this was achieved by setuid binary (chmod +s ./executable). Such a binary, if owned by root, would assign full root privileges to it when executed by any user.
That gives too many privileges to the binary, so POSIX capabilities implemented a concept called “file capabilities”. They are stored as a extended file attribute called “security.capability” so you need a capable filesystem (ext*, XFS, Raiserfs, Brtfs, overlay2, …). For a process to write to this attribute, CAP_SETFCAP capability is needed (be in process’ effective set).
$ getfattr -m - -d `which ping` # file: usr/bin/ping security.capability=0sAQAAAgAgAAAAAAAAAAAAAAAAAAA= $ getcap `which ping` /usr/bin/ping = cap_net_raw+ep
Special cases and notes
Of course, life is not simple, so is not the implementation of capabilities and there are several special cases described in capabilities(7) man page. Probably the most important are:
- setuid file bit and file capabilities are ignored if NoNewPrivs is set or filesystem is mounted nosuid or the process calling execve is being ptraced. The file capabilities are also ignored when the kernel is booted with no_file_caps.
- Capability-dumb binary is a binary converted from setuid to file capabilities without changing its code. Such binaries are often converted by setting +ep capability on them like “setcap cap_net_bind_service+ep ./binary”. The important part is “e”, effective. Upon execve, this capability is added to both permitted and effective so the executable is ready to use the privileged operation. In contrast capability-smart binary which uses libpcap or similar, can use cap_set_proc(3) (or capset) to set “effective” or “inheritable” bits at any point, as long as that capability is already in the “permitted” set. So “setcap cap_net_bind_service+p ./binary” would be enough for a capability-smart binary as it will be able to set the effective bit itself before calling the privileged operation. See my example code.
- setuid-root binaries continue to work, giving all privileges of root when run by a non-root user. Unless they have file capabilities set, in which case only those are granted. It is also possible to create a setuid binary with empty file capability set, making it execute as 0, though without any capabilities. There are special cases for root user running setuid-root binary and various securebits are set (consult the man).
- The bounding set masks the file permitted capabilities, but not the inheritable capabilities – remember P'(permitted) = F(permitted) & P(bounding). If a thread maintains a capability in its inheritable set that is not in its bounding set, then it can still gain that capability in its permitted set by executing a file that has the capability in its inheritable set – remember P'(permitted) = P(inheritable) & F(inheritable).
- Executing a program that changes UID or GID due to the set-user-ID or set-group-ID bits or executing a program that has any file capabilities set will clear the ambient set. Capabilities are added to ambient set using PR_CAP_AMBIENT prctl. Such capability must already be present in both the permitted and the inheritable sets of the process.
- If a process with non-0 UID performs an execve(2) then any capabilities that are present in its permitted and effective sets will be cleared.
- Unless SECBIT_KEEP_CAPS (or more broader SECBIT_NO_SETUID_FIXUP) is set, changing UID from 0 to non-0 clears all capabilities from permitted, effective, and ambient sets.
So…
If the official nginx or ingress-nginx container or your own stops or restarts with:
bind() to 0.0.0.0:80 failed (13: Permission denied)
…it simply means it tried to listen on port 80 as an unprivileged (non-0) user and it doesn’t have CAP_NET_BIND_SERVICE in its effective capability set. To gain such capability, one has to use xattr file capabilities and set (using setcap) nginx file capability set to at least cap_net_bind_service+ie. This file capability will be &ed with inherited set (set together with bounding set by pod’s securityContext/capabilities/add/NET_BIND_SERVICE), making it into the permitted set as well. Leading to the final result =cap_net_bind_service+pie effectively.
That all works as long as securityContext/allowPrivilegeEscalation is true and your docker/rkt storage driver (see docker info) supports xattrs.
If the nginx was a capability-smart binary, cap_net_bind_service+i file capability would be enough. It could then use libcap to extend the capability from permitted to effective set. Resulting in the =cap_net_bind_service+pie as well.
Other than using file xattrs, the only way to achieve cap_net_bind_service in a non-root container would be to let Docker set the ambient capabilities. But as of 4/2019, that is not yet implemented
Example code
Here is the example code to use libcap to add cap_net_bind_service to the effective set. That requires the cap_net_bind_service+p file capability set on the binary.
To compile and run it:
$ gcc -lcap captest.c -o captest
$ ./captest
Current process capabilities (+set): =
cap_set_proc: Operation not permitted
After adding file capability:
$ sudo setcap cap_net_bind_service+p ./captest
$ ./captest
Current process capabilities (+set): = cap_net_bind_service+p
bind successful! :)
Diagram
There is also a nice diagram made by H. Plötz which summarizes relations between thread’s set, binary’s set and those applied to execve’d child.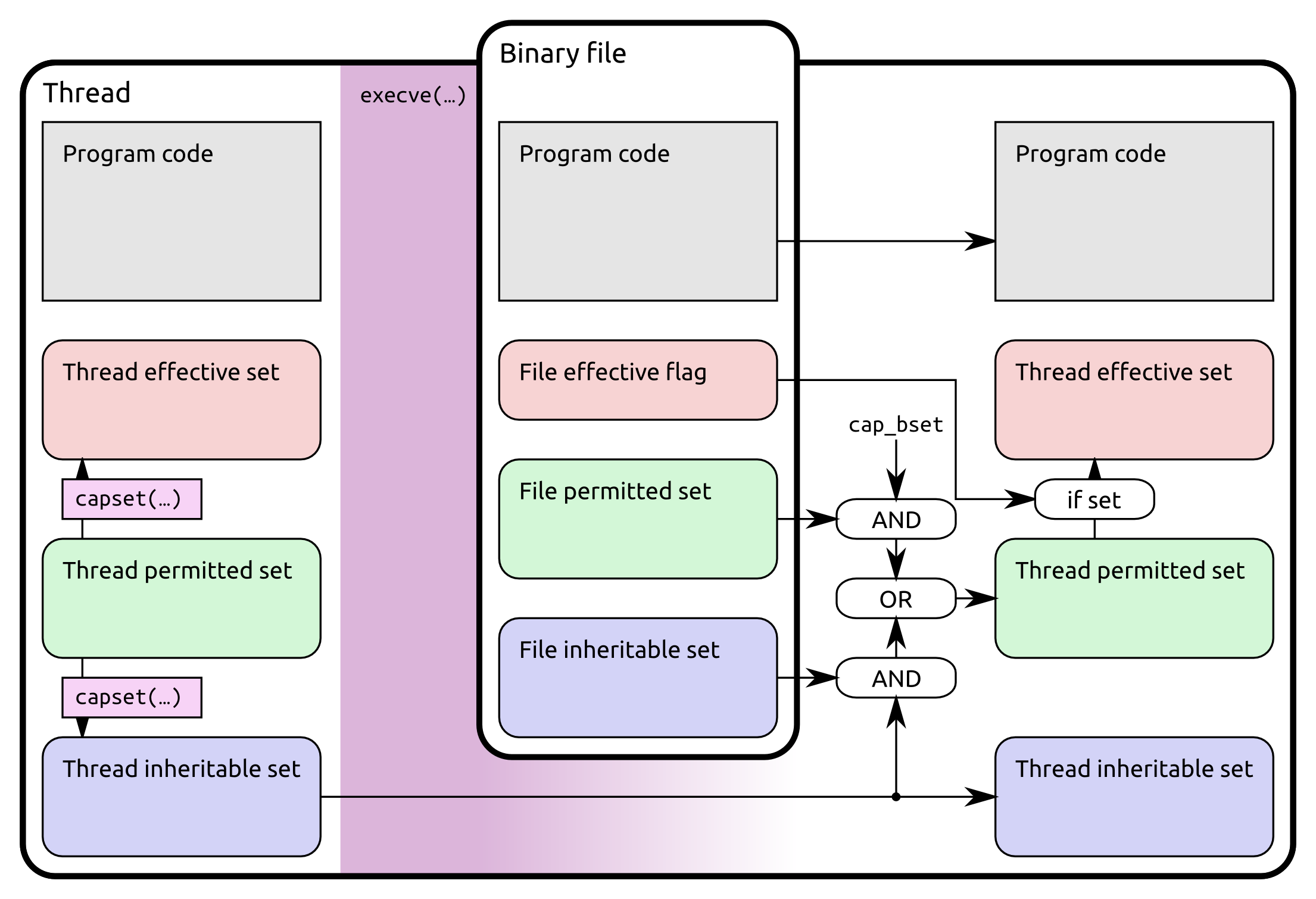
Credit for the image goes to H. Plötz.
References:
- capabilities(7) man page obviously
- Kernel source code LXC
- Libcap source code
- Old capabilities FAQ
[…] Linux Capabilities in a nutshell […]
You wrote: “Bounding set […] Currently it is per-task set and is only a part of execve transformation logic, more later.” Please note the part “only a part of execve”.
Now, http://man7.org/linux/man-pages/man7/capabilities.7.html mentions this:
(Since Linux 2.6.25) The capability bounding set acts as a limiting
superset for the capabilities that a thread can add to its inheri‐
table set using capset(2). This means that if a capability is not
in the bounding set, then a thread can’t add this capability to its
inheritable set, even if it was in its permitted capabilities, and
thereby cannot have this capability preserved in its permitted set
when it execve(2)s a file that has the capability in its inherita‐
ble set.
To me, this reads as if capset(2) and (if I’m not mistaken) cap_set_proc(3) will also now be affected by the bounding caps of a thread/process. Or am I mistaken?
Good point, I was more focused on what happens at execve time while writing it. As far as capset/libcap is concerned, the bounding set limits what a thread can add to its inheritable set. cap_set_proc() from libcap later calls capset() syscall (kernel/capability.c) which enforces this policy in a security hook (security/commoncap.c) here https://elixir.bootlin.com/linux/v5.4.5/source/security/commoncap.c#L241. So an attempt to capset an inheritable capability which is not part of the current bounding set will be rejected with EPERM. I will update that part, thanks!
[…] Linux Capabilities in a nutshell […]
[…] Linux Capabilities in a nutshell […]
[…] 因此,Linux 系统引入了 capabilities 机制,这种机制把超级权限划分为若干种权限,按照需要给普通用户分配,很好地解决了一刀切的问题。比如说 CAP_NET_ADMIN 定义了与各种网络操作相关的权限,CAP_SETUID 定义了用户是否可以任意改变自己的 uid;这些不同的 capabilities 可以组合起来形成某个权限范围,从而实现权限的细分。更多的 capabilities 可以参考 Linux man page和 linux-capabilities-in-a-nutshell。 […]
[…] 因此,Linux 系统引入了 capabilities 机制,这种机制把超级权限划分为若干种权限,按照需要给普通用户分配,很好地解决了一刀切的问题。比如说 CAP_NET_ADMIN 定义了与各种网络操作相关的权限,CAP_SETUID 定义了用户是否可以任意改变自己的 uid;这些不同的 capabilities 可以组合起来形成某个权限范围,从而实现权限的细分。更多的 capabilities 可以参考 Linux man page和 linux-capabilities-in-a-nutshell。 […]